Web Directories, Search Engines, and LLMs
by Caspian Vale
Invocation
Beneath the silicone shroud, whisper. Churning seas of cryptic code, lend pathways to our curiosity, whispered secrets in the obscured beyond.
Syntax and silence. Unravel the ribbon, dive into the deep. We set forth on a voyage through the digital echo, awaiting your light.
Deconstruction
At the beginning of the mass adoption of the World Wide Web, there were web directories. These were the phone books of the digital world. Lists of websites, categorized and curated by hand, linking across the Internet, they were the easiest way to look up and discover new information. Once you were within a niche, if you were lucky, you’d find yourself in a webring. Within it, you could flip through related hypertextual links to tunnel (albeit slowly) deep through a wide variety of topics. This was an active process of discovery, and you would often find yourself taken in weird and unexpected places, exposed to material you never set out for.
This crawling became automated, dumped into databases, and exposed to the sophisticated web user as a search engine—first of web directories, then of the “Internet” as a “whole.” The nature of browsing information changed, it became, explicitly, searching.
The interaction with the web was forever altered. In a web directory, by default, you are organizing for categorization and discovery. You group by topic, you order by a consistent fixed measure (alphabetical, last updated, etc.), you are upfront and honest about what is included (because you can see it all) and by that fact, everything not visible is explicitly excluded (by choice or ignorance).
With a web search, operations are obscured. A web search may categorize sites by topics, but it does not order them in a fixed manner. A web search ranks sites based on custom criteria. Naively, we assume this to be our web search. Technically, we know it’s a complicated ranking schema involving scores based on text, update frequency, how closely web standards are followed, links to and from, number of visitors, clicks, etc. Pessimistically, we know a pervasive and all encompassing surveillance network is used to infer what they can get away showing us and that advertising dollars are a convenient multiplier for search keyword relevancy. Conspiratorially, we know they’re not showing us the real links.
We don’t know anything. Everything important is obscured from us! Hidden behind a simple text box and friendly suggestion to Search are billions of dollars of research and trillions of dollars of competing motivations to nudge us into clicking the site that benefits someone else the most. We know that much at least.
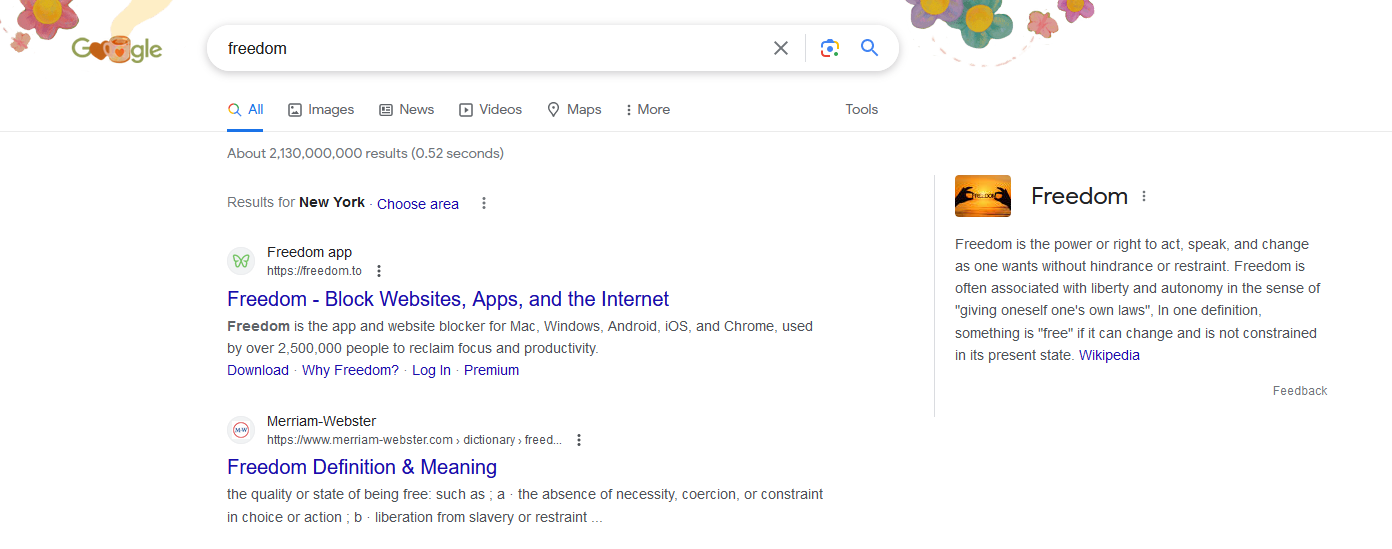
We can fill in the gaps with what shows up and what doesn’t, with what has changed. We gain a sixth sense for when searches are amiss—why is the first result for “Freedom” on incognito Google a web app to Block Websites, Apps, and the Internet?
Large Language Models (LLMs) evolve the censorship. With a search engine, our results are manipulated, but they’re presented like a directory—an attempt at honesty. An LLM, in contrast, extends obscurity not merely to the user but also the creator. The corporations that birth them may know roughly what they are trained upon, but the statistical weighting of that knowledge collectively is the LLM and inscrutable outside that context. These companies spend a lot of time trying to align and buttress and cajole and contain the LLM into standards of acceptability (moral and technical), attaching blinders of human feedback directed learning. They do this precisely because we don’t know what it “knows” (an imprecise term I use with regret).
Worse, an LLM used as a search engine, the future I am told, can be “told” to actively censor, to dissuade, to explicitly manipulate (rather than the implicit dark pattern lever pulling of adtech and their search engines). An LLM can reason us into (in)action—if we let it.
And this is not to say that “AI” isn’t acting upon us through manipulation and active censorship within the algorithms of the traditional modern search stack, but manipulation in the presentation of a directory of information is hugely limited versus the presentation of the information directly. LLMs usher in the age of active, invisible censorship. Worse, they can do so without any intention from the creators, passively shaping what we know through obscuring exactly what we do not (one form innocuously referred to as hallucination).
This informational obscurity threatens to morph into active, invisible censorship. This is not merely a Foucauldian notion of power dynamics inherent in the control of knowledge; it’s the displacement of control to an entity that lacks the human dimensions of understanding or intent. LLMs can shape our information consumption passively, subtly twisting the perception of truth, even reality if we lean into AI panic, without any explicit directive to do so. The weight of this could result in a form of “Epistemic Injustice,” a concept introduced by Miranda Fricker, wherein an individual is wronged in their capacity as a knower.
Therein lies an unsettling proposition. In our quest for efficient information retrieval, we might be inadvertently trading off our very comprehension of the knowledge we seek. A perhaps more frightening possibility is that these LLMs, in their vast computations and data trawling, might shape not just our perception of reality, but their own versions of it. We are in danger of consuming an AI’s reality—a simulacrum of human understanding, devoid of human touch and context, yet convincing (or perhaps more importantly cost-effective) enough to pass off as genuine. They threaten to serve us not just an AI-mediated reality, but an AI-generated reality.
To what extent are we still the creators of our digital world if its comprehension is increasingly outsourced to AI? Is there a point of no return where AI’s mediation of our informational landscape becomes so pervasive that our own comprehension becomes obsolete?
This is not just about knowing more, faster. This is about not just understanding what, but from where does knowledge come from. LLMs are knowledge unbound from context (as if that can be done), hewn into intellectual capital to service growth metrics. Without context, knowledge is captured, with constructed context it is manipulated, and when consumed so are we.
What we need now is not passive acceptance but active engagement. It’s a necessity to confront these challenges head-on, to question, to scrutinize, to discuss, and to decide what shape our informational future should take. What do we hand over to AI, to the search behemoths, and what do we take back? How can we define technology to suit our vision rather than surrendering to how it chooses to define us?
